
High Availability
OmniSci provides support for High Availability (HA) to help your business meet service-level agreements for performance and up time.
OmniSci HA provides redundancy to eliminate single points of failure, and crossover systems that continue operations when a component goes offline.
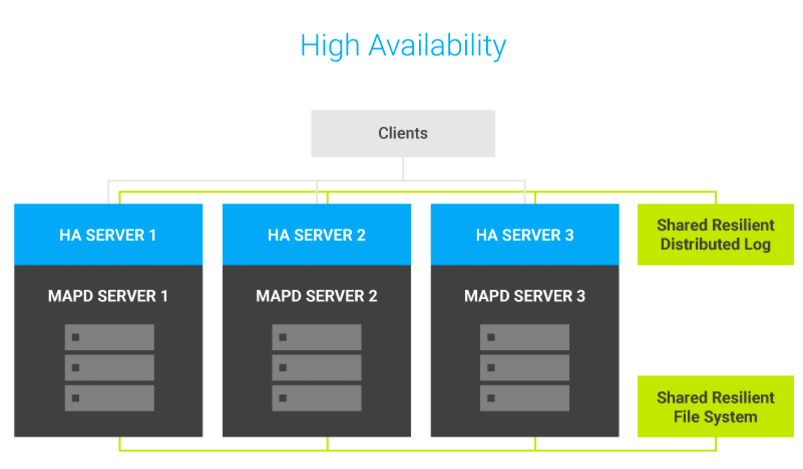
When a server is running in HA mode, it is assigned to a specific HA group. All servers in the HA group eventually receive all updates applied to any server in the same HA group.
Redundancy
Incoming bulk data is seamlessly distributed to multiple OmniSci databases. As HA group members receive each update, backend synchronization orchestrates and manages replication, then updates the OmniSci servers in the HA group using Kakfa topics as a distributed resilient logging system.
To avoid double handling of larger file-based bulk operations such as COPY FROM, OmniSci HA uses a distributed redundant file system to store data. All nodes in the HA group must have access to the distributed file system. By default, the GlusterFS distributed file system is installed, but you can use most any fully featured DFS.
Load Balancing and Failure Detection
The OmniSci HA server uses load balancing to maximize performance and reliability. A load balancer distributes users across the available OmniSci Servers, allowing improved concurrency and throughput as more servers are added. If a OmniSci server becomes unavailable, the load balancer redirects traffic to a different available OmniSci server, preserving availability with a reduction in capacity.
Load balancing can be done with purpose-build hardware such as F5 or mid-tier application servers such as haproxy or node.js. In some circumstances, the application might take into consideration data locality, routing similar requests to the same server to improve performance or reduce GPU memory usage.
Currently, OmniSci does not natively support in-session recovery; a new session must be established after failure. Typically, mid-tier application servers handle this by retrying a request when detecting a connection failure.
HA and OmniSci Distributed
You can use OmniSci HA with OmniSci distributed configuration, allowing horizontal scale-out. Each OmniSci Server can be configured as a cluster of machines. For more information, see distributed.
OmniSci HA Example
When starting a OmniSci Core Database instance as part of a HA group, you must specify the following options.
| Option | Description |
|---|---|
ha-group-id |
The name of the HA group this server belongs to. This identifies the Kafka topic to be used. The topic must exist in Kafka before this server can start. |
ha-unique-server-id |
A unique ID that identifies this server in the HA group. This should never be changed for the lifetime of the OmniSci Core Database instance. |
ha-brokers |
A list used to identify Kafka brokers available to manage the system. |
ha-shared-data |
The parent directory of the distributed file system. Used to check that bulk load files are placed in a directory available to all HA group members. |
A mapd.conf file would look like this.
port = 9091
http-port = 9090
data = "/home/ec2-user/prod/mapd-storage/data"
read-only = false
quiet = false
ha-group-id=hag-group-1
ha-unique-server-id=mymachine
ha-brokers=mykafkabrokerlist
ha-shared-data=/mnt/dfs/mapd-storage/
[web]
port = 9092
frontend = "/home/ec2-user/prod/mapd/frontend"
Implementing HA
Contact OmniSci support for assistance with OmniSci HA implementation.
Implementation Notes
- You can configure your Kafka queue to determine how long it will persist data. Your Kafka server must hold data long enough for full data recovery. In the official Kafka documentation, see the log.retention.[time_unit] settings for Topic-Level Configs.
- OmniSci is not recommended as system of record. $MAPD_STORAGE should not be the basis for data recovery.
- StreamImporter is not supported in HA mode.