Vega Tutorials
Vega is a visualization specification language that describes how to map your source data to your viewing area. By creating a JSON Vega specification structure, you define the data and the transformations to apply to the data to produce meaningful visualizations. The specification includes the geometric shape that represents your data, scaling properties that map the data to the visualization area, and graphical rendering properties.
OmniSci uses Vega for backend rendering. Using the OmniSci Connector API, the client sends the Vega JSON to the backend, which renders the visualization and returns a PNG image for display. See the MapD Charting Examples for backend rendering examples.
These tutorials introduce you to common Vega specification patterns so you can start creating visualizations quickly and easily. Each tutorial uses a code example that demonstrates a particular Vega feature or pattern. The Getting Started with Vega tutorial covers basic Vega concepts using the tweets example you saw in Vega at a Glance. It serves as the foundation for the tutorials that follow, and introduces you to the API for communication with the backend. After you understand the fundamental Vega concepts presented in these tutorials, refer to the Vega Reference document to create more complex visualizations using the full capabilities of Vega.
You can find the source code for each tutorial in the Example Source Code document. These and the MapD Charting Examples can be used to gain a better understanding of Vega by experimenting with them to create new visualizations on your own OmniSci system and database.
Tutorial Framework
Because the tutorials focus on the Vega specification, they use a simple client implementation that sends the render request to the OmniSci server and handles the response:
<!DOCTYPE html>
<html lang="en">
<head>
<title>OmniSci</title>
<meta charset="UTF-8">
</head>
<body>
<script src="js/browser-connector.js"></script>
<script src="js/vegaspec.js"></script>
<script src="js/vegademo.js"></script>
<script>
document.addEventListener('DOMContentLoaded', init, false);
</script>
</body>
</html>
function init() {
var conn = new MapdCon()
.protocol("http")
.host("my.host.com")
.port("6273")
.dbName("omnisci")
.user("omnisci")
.password("changeme")
.connect(function(error, con) {
con.renderVega(1, JSON.stringify(exampleVega), vegaOptions, function(error, result) {
if (error) {
console.log(error.message);
}
else {
var blobUrl = `data:image/png;base64,${result.image}`
var body = document.querySelector('body')
var vegaImg = new Image()
vegaImg.src = blobUrl
body.append(vegaImg)
}
});
});
}
The renderVega() function sends the exampleVega JSON structure described in the tutorials. The first, Getting Started with Vega tutorial covers Vega library dependencies and the renderVega() function in more detail.
Finding the Cause of Errors
On a connection error, you can view the error message to determine the cause of the error. To determine the cause of Vega specification errors, catch and handle the renderVega() exception, as shown.
Getting Started with Vega
Source code: Getting Started
This tutorial uses the same visualization used in the Vega at a Glance document but elaborates on the runtime environment and implementation steps. The Vega usage pattern described here applies to all Vega implementations. Subsequent tutorials differ only in describing more advanced Vega features.
This visualization maps a continuous, quantitative input domain to a continuous output range. Again, the visualization shows tweets in the EMEA region, from a tweets data table:
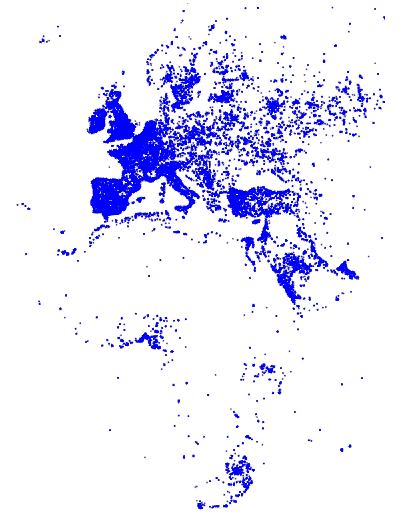
Backend rendering using Vega involves the following steps:
You can create the Vega specification statically, as shown in this tutorial, or programmatically. See the Poly Map with Backend Rendering charting example for a programmatic implementation. Here is the programmatic source code:
Step 1 - Create the Vega Specification
A Vega JSON specification has the following general structure:
const exampleVega = {
width: <numeric>,
height: <numeric>,
data: [ ... ],
scales: [ ... ],
marks: [ ... ]
};Specify the Visualization Area
The width and height properties define the width and height of your visualization area, in pixels:
const exampleVega = {
width: 384,
height: 564,
data: [ ... ],
scales: [ ... ],
marks: [ ... ]
};Specify the Data Source
This example uses the following SQL statement to get the tweets data:
data: [
{
"name": "tweets",
"sql": "SELECT goog_x as x, goog_y as y, tweets_nov_feb.rowid FROM tweets_nov_feb"
}
]The input data are the latitude and longitude coordinates of tweets from the tweets_nov_feb data table. The coordinates are labeled x and y for Field Reference in the marks property, which references the data using the tweets name.
Specify the Graphical Properties of the Rendered Data Item
The marks property specifies the graphical attributes of how each data item is rendered:
marks: [
{
type: "points",
from: {
data: "tweets"
},
properties: {
x: {
scale: "x",
field: "x"
},
y: {
scale: "y",
field: "y"
},
"fillColor": "blue",
size: {
value: 3
}
}
}
]In this example, each data item from the tweets data table is rendered as a point. The points marks type includes position, fill color, and size attributes. The marks property specifies how to visually encode points according to these attributes. Points in this example are three pixels in diameter and colored blue.
Points are scaled to the visualization area using the scales property.
Specify How Input Data are Scaled to the Visualization Area
The following scales specification maps marks to the visualization area.
scales: [
{
name: "x",
type: "linear",
domain: [
-3650484.1235206556,
7413325.514451755
],
range: "width"
},
{
name: "y",
type: "linear",
domain: [
-5778161.9183506705,
10471808.487466192
],
range: "height"
}
]Both x and y scales specify a linear mapping of the continuous, quantitative input domain to a continuous output range. In this example, input data values are transformed to predefined width and height range values.
Later tutorials show how to specify data transformation using discrete domain-to-range mapping.
Step 2 - Connect to the Backend
Use the browser-connector.js renderVega() API to communicate with the backend. The connector is layered on Apache Thrift for cross-language client communication with the server.
Follow these steps to instantiate the connector and to connect to the backend:
- Include
browser-connector.jslocated at https://github.com/omnisci/mapd-connector/tree/master/dist to include the MapD connector and Thrift interface APIs.
<script src="<localJSdir>/browser-connector.js"></script>
- Instantiate the
MapdCon()connector and set the server name, protocol information, and your authentication credentials, as described in the MapD Connector API:
var vegaOptions = {}
var connector = new MapdCon()
.protocol("http")
.host("my.host.com")
.port("6273")
.dbName("omnisci")
.user("omnisci")
.password("HyperInteractive")
| Property | Description |
|---|---|
dbName |
OmniSci database name. |
host |
OmniSci web server name. |
password |
OmniSci user password. |
port |
OmniSci web server port |
protocol |
Communication protocol: http, https |
user |
OmniSci user name. |
- Finally, call the MapD connector API connect() function to initiate a connect request, passing a callback function with a
(error, success)signature as the parameter.
.connect(function(error, con) { ... });
The connect() function generates client and session IDs for this connection instance, which are unique for each instance and are used in subsequent API calls for the session.
On a successful connection, the callback function is called. The callback function in this example calls the renderVega() function.
Step 3 - Make the Render Request and Handle the Response
The MapD connector API renderVega() function sends the Vega JSON to the backend, and has the following parameters:
.connect(function(error, con) {
con.renderVega(1, JSON.stringify(exampleVega), vegaOptions, function(error, result) {
if (error)
console.log(error.message);
else {
var blobUrl = `data:image/png;base64,${result.image}`
var body = document.querySelector('body')
var vegaImg = new Image()
vegaImg.src = blobUrl
body.append(vegaImg)
}
});
});| Parameter | Type | Required | Description |
|---|---|---|---|
widgetid |
number | X | Calling widget ID. |
vega |
string | X | Vega JSON object, as described in Step 1 - Create the Vega Specification. |
options |
number | Render query options.
PNG compression level.
1 (low, fast) to 10 (high, slow). Default = 3 |
|
callback |
function | Callback function with (error, success) signature. |
| Return | Description |
|---|---|
| Base64 image | PNG image rendered on server |
The backend returns the rendered Base64 image in results.image, which you can display in the browser window using a data URI.
Summary
This tutorial reviewed the Vega specification, showed you how to set up your environment to communicate with the backend, and showed how to use renderVega() to make a render request. These basic concepts are the foundation of the remaining tutorials, which focus on other Vega features.